 “Why does my sister have different ethnicity percentages than I do?” “Why does my brother have different genetic cousins than I do?” “If we have the same parents, then shouldn’t we have the same ethnicity or the same relatives?” If you have had these questions regarding your DNA test results, you are not alone! These are some of the most common questions about genetic genealogy tests that we receive from our clients and our readers. If you have these questions, it also indicates that you are ready to incorporate your DNA test results into your family history research and explore the concept of DNA coverage.
“Why does my sister have different ethnicity percentages than I do?” “Why does my brother have different genetic cousins than I do?” “If we have the same parents, then shouldn’t we have the same ethnicity or the same relatives?” If you have had these questions regarding your DNA test results, you are not alone! These are some of the most common questions about genetic genealogy tests that we receive from our clients and our readers. If you have these questions, it also indicates that you are ready to incorporate your DNA test results into your family history research and explore the concept of DNA coverage.
Your ethnicity estimates and genetic cousin match lists may differ from those of your close relatives because of the unique inheritance patterns of autosomal DNA – the type of DNA on which these ethnicity estimates and relative lists are based. Due to these inheritance patterns, different descendants of a common ancestor may share some DNA with each other, but will also inherit unique portions of that ancestor’s DNA which they do not share in common. This inheritance pattern not only explains why siblings have different test results; it also shows why collaboration, planning, and targeted testing are necessary components of achieving genealogical proof with DNA evidence.
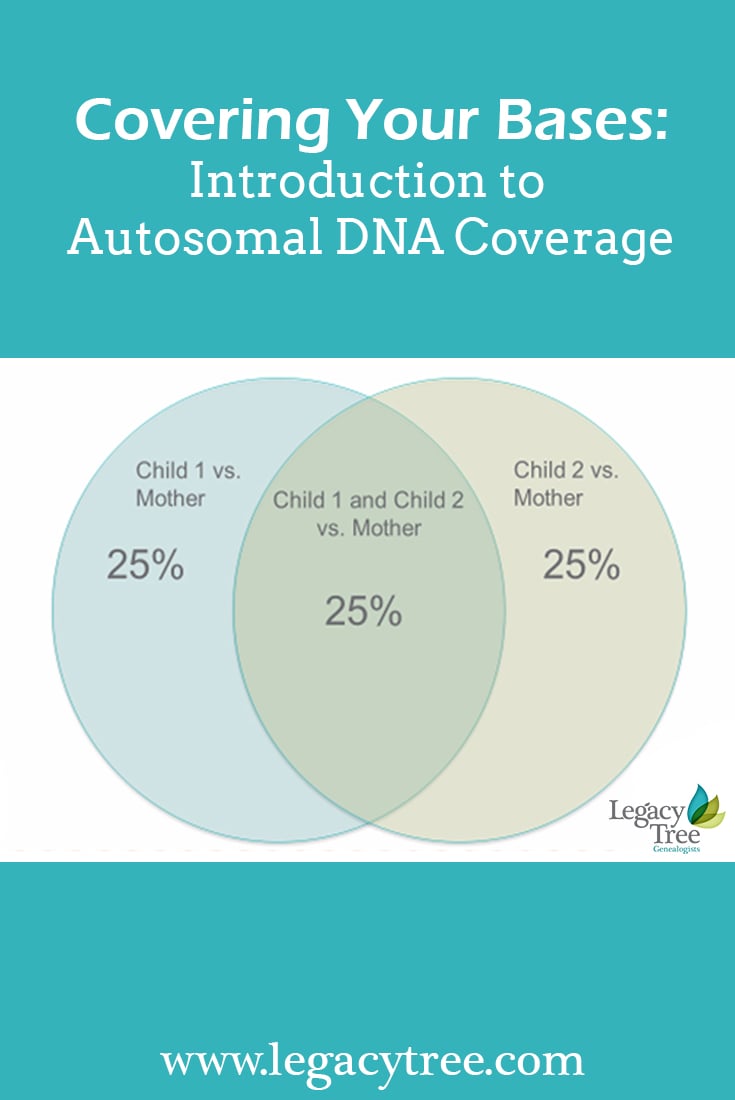
In humans, autosomal DNA is composed of 22 pairs of chromosomes found in the nucleus of the cell. Each individual inherits one set of chromosomes from their mother and a corresponding set of chromosomes from their father. Therefore, each individual gets 50% of their autosomal DNA from each of their parents. The amount of DNA inherited from more distant ancestors is only approximate due to a random process called recombination which shuffles the DNA each generation. Each individual inherits about 25% from each grandparent, about 12.5% from each great-grandparent and approximately half again for each previous generation. Although you inherit 50% of your DNA from your mother and your sibling also inherits 50% of their DNA from your mother, the portions of DNA you inherit are not exactly the same unless you are identical twins. On average, two full siblings will share 25% of their maternal DNA and 25% of their paternal DNA with each other. By extension, each sibling will inherit 25% of their maternal DNA and 25% of their paternal DNA which is unique from another sibling.

Because of these inheritance patterns, one sibling might have inherited a larger portion of DNA from the mother’s African ancestors, while the other sibling might have inherited a slightly larger portion of DNA from the mother’s European ancestors. In the context of genetic match lists, one sibling might inherit more DNA from a particular branch of his mother’s family tree than another sibling. Because genetic cousins are identified based on shared DNA, one sibling might share more with a known relative than the other sibling. Ethnicity percentages and genetic relationships to other tested individuals are dependent on the DNA that an individual happened to inherit from their parents and more distant ancestors. While we have explored autosomal inheritance in the context of sibling relationships, the same principles apply to more distant levels of relationship. However, more distant relatives share even less DNA in common with each other. Not only do these inheritance patterns help explain the differences between the test results of close relatives, they also help explain why collaboration, planning, and targeted testing of multiple descendants are important for applying DNA test results to genealogical research.
At Legacy Tree, we frequently incorporate DNA evidence into our research as we seek to break through particularly challenging brick walls, such as in this recent client project. While cases of recent unknown or misattributed parentage can sometimes be solved with just a single DNA test, research goals from the 19th century and earlier are frequently more difficult to solve. Your DNA may not be the best resource for adequately addressing a research goal. If you the research subject is your great-grandfather, then your DNA results will only include about 12% of that ancestor’s DNA. At times, achieving genealogical proof to answer a research question requires targeted testing of additional descendants, relatives, and potential relatives of a research subject. The goal of these efforts is to maximize the coverage of a research subject’s DNA in any given DNA database.
Introduction to DNA Coverage
Coverage refers to the amount of a research subject’s DNA that is represented in a DNA database through their combined tested descendants. As mentioned previously, you inherit 50% of your DNA from each of your parents. Considered from another perspective, this means that by testing yourself, 50% of your mother’s DNA is represented or “covered” in a DNA database. If you are interested in learning more about your mother’s unknown ancestry, then your own DNA would “cover” 50% of her DNA which you could utilize in analysis of her relatives and relationships. As shown above, if you and a sibling performed DNA testing, you would each share 50% of your DNA with your mother, but overall you would achieve 75% coverage of her DNA. With increased coverage of your mother’s DNA, you would get a better picture of her ancestry, connect with more relatives, and have better chances of solving family mysteries.
An analogy might be the illumination of a portrait in a dark room. If the DNA of the research subject is the painting, then one descendant’s DNA test might be compared to a single flashlight pointed at the painting. While that single light illuminates part of the picture, it only provides a portion of the complete story. The portion of the painting illuminated by different descendants might be larger for some than for others based on their relationship to the research subject. Grandchildren will have larger illuminations than great grandchildren. By recruiting additional descendants to test, it is possible to illuminate more of the complete picture.

While testing multiple descendants of a research subject is useful, not all descendants are equally important. Whenever possible testing candidates should be recruited from unique descent lines, because they inherit more unique DNA and therefore result in higher coverage. Consider, for example if your research subject is your great-grandmother. Your DNA test would result in about 12% coverage of her DNA. If you were to test your sibling, you would get 75% coverage of your father’s DNA, the test subject’s grandson, but you would only get about 19% coverage of your research subject’s DNA. Even if you were to test yourself and four of your siblings (scenario 1 below), the coverage you could expect to achieve of your great-grandmother’s DNA would be limited by the DNA that your father inherited from that same ancestor: about 25%. Meanwhile, if you were to test yourself and four first cousins through unique descent lines (scenario 2), you could achieve approximately 38% coverage of your great-grandmother’s DNA. Even better, if you tested yourself and four second cousins through unique descent lines (scenario 3), you could achieve approximately 49% coverage of your great-grandmother’s DNA.
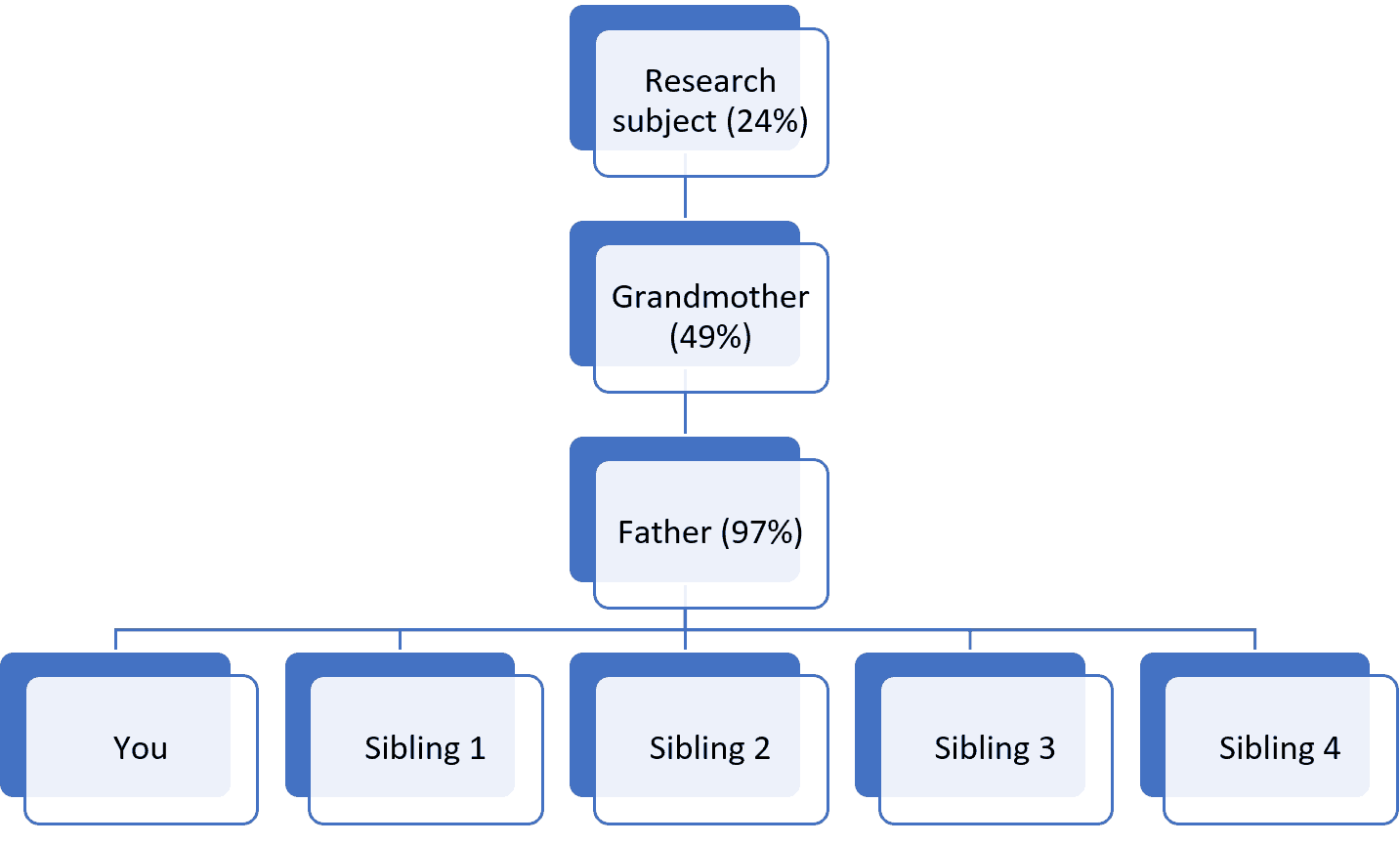

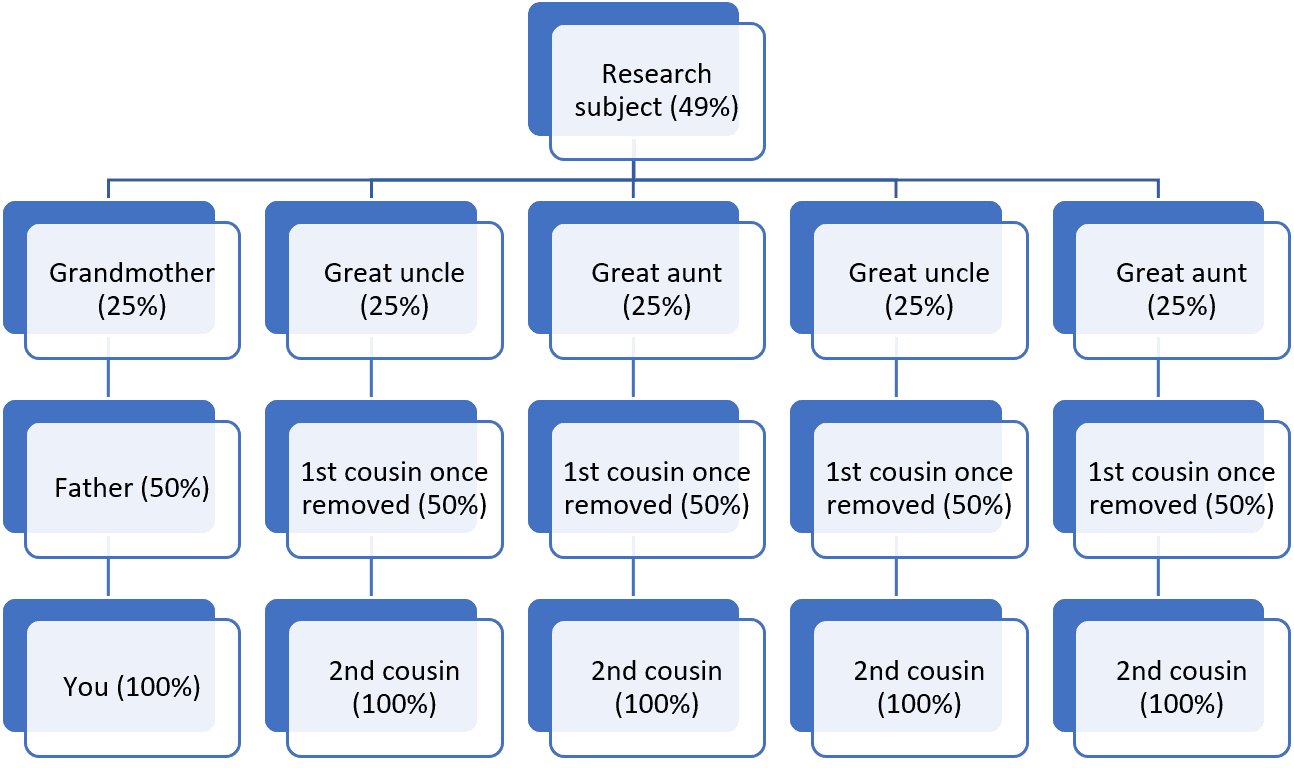
Given these observations, when attempting to maximize the coverage of an ancestor’s DNA, you should consider testing descendants from unique descent lines.
DNA Coverage Calculations
If a test subject has a coverage of 100% (or 1), then their DNA will cover 50% (or.5) of the DNA of a parent. In the following equations, C = coverage of the research subject. To simplify the equations, we have chosen to account for the fact that a child will cover 50% of a single parent’s DNA. Therefore, a = ½ the coverage of child A, b = ½ the coverage of child B, c = ½ the coverage of child C, and d = ½ the coverage of child D. When calculating coverage of a research subject, we recommend calculating the coverage at each branch point in the individual’s tree. For example, if a research subject had three children who had descendants, the coverage of each child should be calculated before calculating the coverage of the research subject.
Coverage equation for a subject with one child: C = a
Coverage equation for a subject with two children: C = a + b – ab
Coverage equation for a subject with three children: C = a + b + c – ab – ac – bc + abc
Coverage equation for a subject with four children: C = a + b + c + d – ab – ac – ad – bc – bd – cd + abc + abd + acd + bcd – abcd
Coverage equation for a subject with five children: C = a + b + c + d + e – ab – ac – ad -ae – bc – bd – be – cd – ce – de + abc + abd +abe + acd +ace + ade + bcd + bce + bde + cde – abcd – abce – abde – acde – bcde + abcde
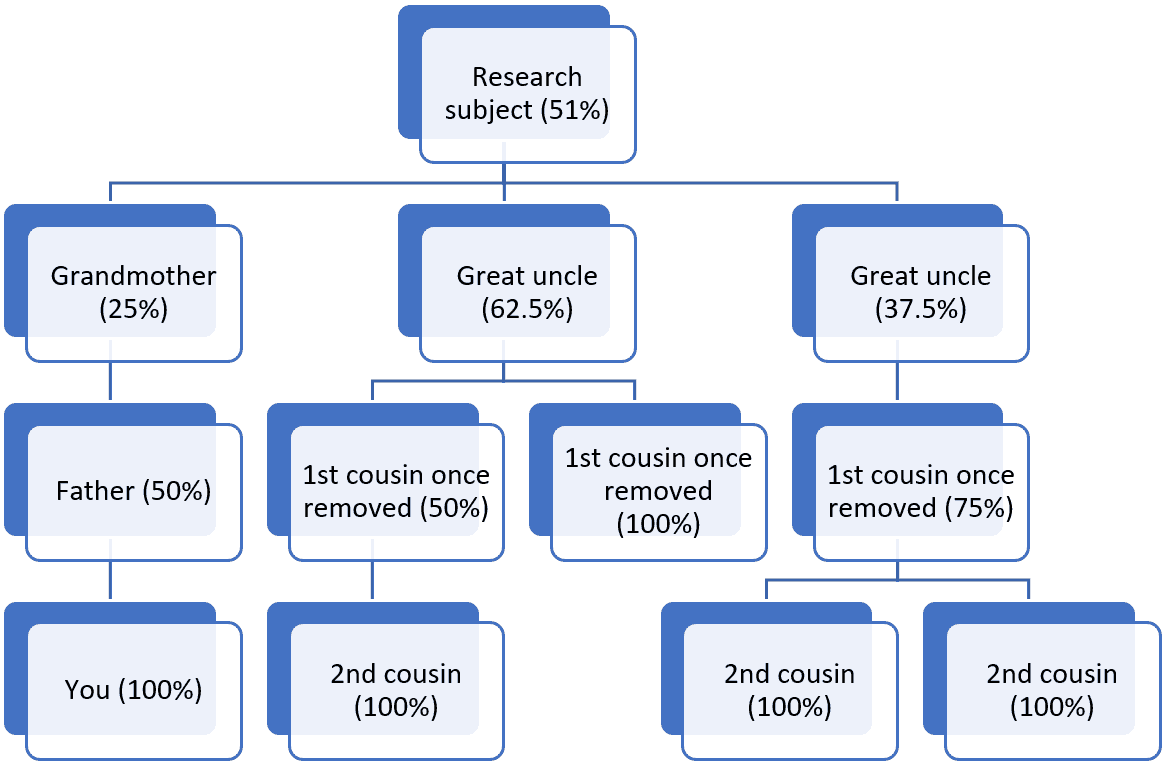
When estimating the coverage of a research subject, calculate the coverage for each intervening generation. This is straightforward if there is only one tested descendant along a particular line, but can be more complicated for multiple descendants. For example, in the following scenario, the coverage of the first child of the research subject is .25 (1 ÷ 2 ÷ 2). Coverage for the second child is .625 (.5 + .25 – (.5 x .25)). Coverage for the third child is .375 ((.5 +.5 – (.5 x.5)) ÷ 2). Once we have calculated the coverage for each child, we divide those values by 2 (.125, .3125, and .1875) and we calculate the overall coverage for the research subject. (.125 + .3125 + .1875 – (.125 x .3125) – (.125 x .1875) – (.3125 x .1875) + (.125 x .3125 x .1875). In this scenario, the overall coverage for the research subject is 51%.
Applications for DNA Coverage
Why spend time estimating the coverage of an ancestor? It will probably save you time and money in the long run. Coverage calculations are an important part of DNA testing plans because they help you evaluate whether testing additional relatives could significantly affect the overall coverage of your research subject. By first identifying all living descendants of a research subject and then calculating coverage for different testing scenarios, you can prioritize which relatives to test for a given research goal. Since testing multiple descendants results in a diminishing return on coverage, you can also use these calculations to determine when to stop testing additional relatives. A general guideline we recommend: if the expected increase of coverage from one additional test is greater than 5%, then that relative should be invited to test. If the expected increase of coverage from one additional test is less than 5%, then it may not be worth it to test that relative within the context of the research goal.
Another important application of coverage is the reconstruction of ancestral genomes and estimation of amounts of shared DNA. When multiple descendants of a target ancestor test and transfer their test results to Gedmatch, Family Tree DNA, or MyHeritage, it is possible to identify all unique segments shared between descendants of a research subject and key matches. Based on the coverage of a research subject’s DNA, we can estimate approximately how much DNA a research subject would have shared with a key match and can evaluate relationships without the ambiguity of additional generations of relationship. This approach, however, should be used cautiously as coverage calculations are simply estimates of the amount of a research subject’s DNA represented in a database. As more descendants of a research subject perform testing, these estimates more closely reflect reality.
If you’ve taken a DNA test and need help analyzing the results, or if you have a genealogy question you think DNA might be able to help answer, we would love to help! Contact us to discuss your questions and goals, and we’ll help you choose a project option and get started.
Hi,
I calculated the coverage using your explicit formulas for 1-5 children, and surpassed 100% coverage for 5 children. Do you get these values?
1 0.5
2 0.75
3 0.625
4 0.9375
5 1.0938
Thank you for bringing this to our attention, in fact there are two missing pieces in the five child equation it should read:
C = a + b + c + d + e – ab – ac – ad -ae – bc – bd – be – cd – ce – de + abc + abd +abe + acd +ace + ade + bcd + bce + bde + cde – abcd – abce – abde – acde – bcde + abcde
In short, the five-child equation should add for each child, subtract all pairwise comparisons, add three-way comparisons, subtract four way comparisons and add the five way comparison.
The coverage calculations for 1-5 children should be as follows:
1 child = .5
2 children = .75
3 children = .875 (The calculation for this is .5+.5+.5 -.25-.25-.25 +.125)
4 children = .9375
5 children = .96875. The calculation for this is .5 +.5 +.5 +.5 +.5 -.25-.25-.25-.25-.25-.25-.25-.25-.25-.25+.125+125+.125 +.125 +.125 +.125 +.125 +.125 +.125 +.125-.0625 -.0625 -.0625 -.0625 -.0625+.03125
can you give a general formula for any number of siblings? alternatively the explicit formulas for 6, 7, 8, 9, 10 siblings? or the actual numbers?
Though I have not yet developed a formula for any number of siblings, the general approach is to first take half the coverage of each sibling, and then alternately add and remove progressively larger comparisons.
For two siblings, we half each siblings coverage (a and b), we add a and b and then we subtract the pairwise comparison (ab). For a 7-sibling analysis, we half each sibling’s coverage (a, b, c, d, e, f, and g), add those all together, then we subtract all pairwise comparisons, add all three-way comparisons, subtract all four-way comparisons, add all five-way comparisons, subtract all six-way comparisons and add the seven-way comparison.
I have calculated six, seven and eight siblings to have the following coverages:
6 siblings: .984375
7 siblings: .9921875
8 siblings: .99609375
Coverage = ((2**n) – 1)/(2**n)
where
n is the number of children
and 2**n means 2 to the nth power.
Hi Wesley. This works when all children have a coverage of 1 and all test subjects are at the same generational level. It does not work when you have descendants from different generational levels (i.e. two grandsons on one branch, a grandson and a great grandson on another branch, and two great grandsons on a third branch – each child representing each branch will have a different coverage to start.
I would really like to see this generalized, with the target person being any relative with any combination of relatives also testing.
Simple example: What is the coverage of person X by their child and one of their grandchildren by another of their children? That is, the two others are a child and a grandchild of X and one is the aunt/uncle of the other.
Complicated example: Missing soldier X is the target. What is the coverage of his autosomal DNA by two of his/her 1c1r’s who are siblings of each other? And what if you add to these two a third family member who is a 1c1r on the soldier’s other parent’s side?
I’d really like to see a WATO-interface tool to enter configurations and specify the target person and then tell you the average coverage you can achieve with tests by those relatives.