 Paul Woodbury is a DNA team lead and professional researcher at Legacy Tree Genealogists where he has helped to solve hundreds of genetic genealogy cases. In this article, a reprint from an issue of NGS Magazine, Paul discusses steps a researcher could take to begin using DNA test results. This article is published with permission.
Paul Woodbury is a DNA team lead and professional researcher at Legacy Tree Genealogists where he has helped to solve hundreds of genetic genealogy cases. In this article, a reprint from an issue of NGS Magazine, Paul discusses steps a researcher could take to begin using DNA test results. This article is published with permission.
Several weeks after the submission of a DNA sample, the results finally arrive! An email appears announcing that the test has completed processing. It includes a link to sign in to review the test results. But what comes next? Where to start? The following are my recommendations for the first steps a researcher might take to begin using test results. This article provides a brief overview, and future columns will dig deeper into each of these topics.
Set up a profile and attach a family tree
First, if a profile has not been created, set one up. When considering what to include, review my previous article on this topic. [1]
Adding a profile image, answering questions regarding research interests, listing ancestral surnames, and attaching a family tree to the account can make DNA test results more useful. These items also help make test takers more approachable from the perspective of their newfound genetic cousins.
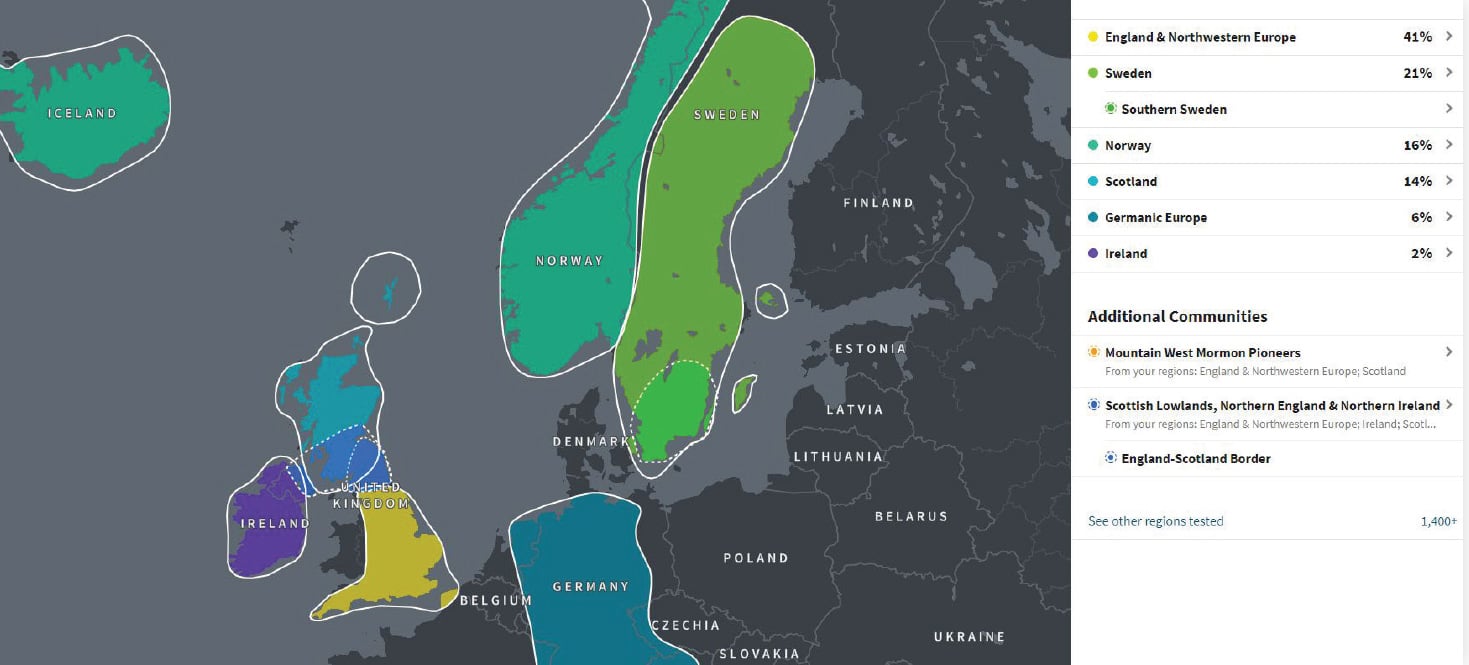
Review ethnicity admixture reports
Ethnicity admixture is one of the major reasons that people initially pursue DNA testing. Each of the testing companies invests attention, advertising, and marketing for this element. While these reports are typically not very helpful for genealogical research questions, they do provide a broad context for other genetic genealogy pursuits. They also provide a good introduction to DNA test results.
Often these results include ethnicity admixture regions indicating the broad geographic areas where a test taker’s ancestors may have lived within the last thousand years as well as more specific genetic communities or ancestral populations that may have been associated with the ancestors in recent centuries.
When evaluating ethnicity admixture reports, researchers might ask these questions:
▪ Does the test taker have significantly more than 50 percent admixture from a particular region? If so, both parents may have ancestry from that region since individuals inherit only 50 percent of their autosomal DNA from each parent.
▪ Does the test taker have an even split between two main ethnic regions? If so, one parent may be from one area and the other parent from the other.
▪ Given the documented family tree of the test taker, do the ethnicity results generally align with expectations? Keep in mind that some populations were historically admixed, so it is possible that admixture from an expected region has been assigned to a neighboring region or otherwise associated region.
▪ Are any admixture regions or results anomalous, given the context of the test taker’s family tree? Anomalous in this context means admixture that is 10 percent higher or lower than would be expected from particular regions and their neighbors.
▪ Do any genetic communities or more specific highlighted ancestral regions fit with what is known regarding the individual’s family tree?
If surprises occur in a test taker’s results, I recommend exploring the anomalies further before jumping to a hasty conclusion. Consider whether unexpected admixture regions might be associated with a known branch of the test taker’s family tree. Explore how the testing company organizes and categorizes specific regions and what ethnic admixture might be expected for individuals from those regions. If an aspect of test results still does not make sense, consider shared matches.

Review the closest genetic cousins
Perhaps the most genealogically useful part of a user’s DNA test results is the list of genetic cousins. Each company presents a list of individuals who are likely related to the test taker based on shared DNA. Shared DNA is measured in centimorgans (cMs), a measure of the likelihood of recombination as well as the number of segments individuals share with each other. The more total centimorgans a test taker and a genetic cousin share, the more likely that they share recent common ancestors.
Some ranges of shared cMs are much more likely for particular relationship levels than they are for others. For example, the amounts of DNA shared between siblings are much larger than the amounts of DNA shared between first cousins. However, with more distant relationships, distinguishing between relationship levels can be more difficult. A third cousin could share as much DNA with a test subject as a fourth cousin, and a fifth cousin could share as much DNA as an eighth cousin.
Each testing company organizes DNA match lists by default based on amounts of shared DNA, with the closest likely relatives listed first. The closest matches in a test taker’s list of genetic cousins are those for whom it is most likely possible to determine the nature of a relationship. Clicking through to view their profiles may give insight into their family trees.
When reviewing the match list of a test taker, researchers might consider these questions:
▪ Have any close relatives of the test taker performed DNA testing? Do they appear in the match list as would be expected?
▪ Do any known relatives share amounts of DNA consistent with their proposed relationships? Keep in mind that half-relatives share half the amount of DNA that would be expected for a full relationship. To evaluate amounts of shared DNA, review the Shared cM Project Calculator at DNA Painter. [2]
▪ Are there any close genetic cousins (sharing more than 200 cM) who are unknown? Do they have family trees that help reveal their likely relationship?
If close tested relatives do not appear in a match list or share less DNA than would be expected, or if unknown close matches appear, consider the possibility of misattributed parentage for either the test subject or the relative. Follow the next steps to aid in determining how they might be related.
Consider shared matches
Interpretation of autosomal DNA test results is established on the principle that when two individuals share DNA with each other, they share a common ancestor. When those two individuals also share matches in common, those shared (or in-common-with) matches are often related through the same ancestral lines.
Analysis of these clusters of shared matches can help researchers categorize groups of matches with specific lines of ancestry and quickly determine how an unknown relative might be related to a test taker.
Identification of these groups can also aid in organizing and filtering a match list to isolate genetic cousins who may be related through a line of interest and whose relationships, in turn, may be pertinent to answering a genealogical research question. This approach for considering shared matches is most effective in non-endogamous populations, where it is most likely that individuals share only a single relationship. [3]
Contact genetic cousins
Once a researcher has determined the likely relationship for an unknown relative or at least determined through which branch of a test subject’s family they are likely related to, it can be beneficial to contact that person to request additional information regarding his or her family tree. When a genetic cousin’s relationship is difficult to determine, collaboration between two individuals can help in the successful determination of the connection.
Each DNA testing company offers avenues for contact with genetic cousins which can aid in establishing relationships of collaboration and cooperation to solve genealogical problems. Even for those genetic cousins whose relationship is known, it may be helpful to establish contact to learn about records, photographs, stories, and information passed down to them through their family or obtained through another person’s family history research efforts.
Take notes
Each testing company offers an interface for annotating important information about genetic cousins. Researchers might record the exact relationship to an individual once it is determined when they attempted contact with the genetic cousin, the maiden name of someone using her married name, or the full name of someone using a vague username. They might even note the relationship path between the test taker and the match to aid in future interpretation.
Even if researchers choose not to record notes in the company interface, they should organize their analysis of relationships using their own note-taking system. They might also create charts to visualize relationships between genetic cousins such as the Smart Art chart shown here.
Search and filter
Each company offers several sets of search functions and filters to aid in organizing and interpreting match lists. Users can search for surnames reported in family trees, usernames, or ancestral surname lists. They might search for locations where their ancestors lived. They might filter the list based on shared DNA, shared ethnicity admixture regions, when an individual appeared as a match, or where a match currently lives.
Exploring these filters can help identify more distant matches who may be related through particular ancestral lines or may share surnames or localities of interest in their family trees.
Explore other company tools
Besides the research avenues listed above, each company offers additional features and tools to aid in the analysis and interpretation of DNA test results. 23andMe offers reports on Y-DNA and mtDNA haplogroups, which might suggest further insights, and reports on physical traits and health information, depending on the test purchased.
Ancestry offers a dot-labeling feature for organizing matches into groups. Its ThruLines seek to identify all genetic cousins in a list showing descent from the reported ancestors of the test subject.
MyHeritage offers an AutoCluster tool to help identify clusters of genetic cousins. Its Theories of Family Relativity generate hypotheses of potential relationship paths between a test taker and genetic cousins.
FamilyTreeDNA, 23andMe, and MyHeritage all offer chromosome browsers to aid researchers in determining and analyzing exactly which segments of DNA are shared between test takers and their matches.
Conclusion
These are some of the first steps a researcher might take when exploring newly processed autosomal DNA test results. In future articles, I will describe each step in more detail and explore other options for using DNA test results to solve genealogical problems.
Getting a DNA test is a great way to start your genealogy journey; however, completing that journey requires hard work and access to the latest tools and services. If you’ve taken a test and need assistance analyzing the results, or if you have a genealogy question you think DNA might be able to answer, we would love to help! Contact us today for a free quote!
References
- Paul Woodbury, “Foundations for Genetic Genealogy Success: Profiles and Family Trees,” NGS Magazine, October-December 2020, 61.
- Jonny Perl, “The Shared cM Project 4.0 tool v4,” DNA Painter (https://dnapainter.com/tools/sharedcmv4, accessed 11 February 2021).
- Endogamous populations have been isolated historically due to geography, language, or religion, resulting in multiple shared ancestors or descent from the same ancestors multiple times. Consequently, a large number of genetic cousins share DNA with many other members of the endogamous population, perhaps through independent relationships.
Deixe um comentário