Paul Woodbury is a DNA team lead and professional researcher at Legacy Tree Genealogists where he has helped to solve hundreds of genetic genealogy cases. In this article, a reprint from an issue of NGS Magazine, Paul discusses how genetic ethnicity estimates can provide valuable clues for the composition of a test taker’s family tree. This article is published with permission.

Obtaining autosomal ethnicity admixture results is the primary reason many people perform DNA testing. The DNA testing companies recognize this interest and in recent years have made genetic ethnicity admixture estimates the focus of their marketing efforts.
In fact, autosomal DNA test results from the major companies include at least two elements: ethnicity admixture estimates and genetic cousin match lists. While the match lists are typically the most useful elements for genealogical research, ethnicity admixture estimates can provide significant context and clues regarding a test taker’s family tree.
What is ethnicity?
An ethnicity is a grouping of people who identify with each other based on shared attributes that distinguish them from other groups, such as traditions, ancestry, language, culture, history, or religion. Individuals of the same ethnicity often belong to the same population (all humans living in a geographic area), and in turn, may share a similar gene pool.
First, it is worth noting that test takers inherit DNA from people rather than places. While some are accustomed to describing their ethnicity admixture in terms of where their DNA came from, people actually inherit DNA from ancestors who lived in populations residing in specific locations rather than from the place where their ancestors lived.
This is an important distinction due to the long history of human migration. While an individual’s more recent ancestors may have lived in the same location for hundreds of years, earlier generations may have come from different and perhaps geographically distant populations—which might result in surprising ethnicity estimates based on genetic information.

Ancestors of a test subject were members of the wider populations in which they lived. Some populations have been isolated from surrounding populations for hundreds to thousands of years due to language, geography, religion, or other factors.
When a population is isolated, the mutations and unique genetic markers generated and commonly held within the population differentiate it genetically from other populations. Other populations have had frequent interaction, migration, and gene flow with surrounding populations, making it difficult to determine which DNA corresponds to historical populations.
While genetic ethnicity estimates would ideally rely on historical DNA samples of individuals who were members of a population, limitations on historical DNA samples require inference of ethnicity based on current populations. However, the boundaries of modern states do not always align well with historically distinct populations.
For example, what is “French” DNA? Is it the DNA of the population of Brittany, which has strong historical connections to the Celtic populations of the British Isles? Is French DNA the DNA of the population of Alsace and Lorraine in eastern France, which has switched between French and German jurisdictions several times over the last several hundred years? Is French DNA the DNA of the Basques on the southern French border, who have been isolated by language and geography for thousands of years? Is French DNA the DNA of people who have lived for generations in and around Paris?
To answer such questions and provide ethnicity estimates, each genetic genealogy testing company relies on some basic principles.
How it works
While each company uses different approaches to provide ethnicity estimates, these methods share some of the same elements: curation of reference panels, the definition of populations, and probability assignment.

In order to determine ethnicity admixture and estimate the populations to which a test taker’s ancestors belonged in the past, the companies first identify individuals whose ancestors all lived in the same region. The companies use extant public databases as well as samples from their own databases to curate a reference panel of samples for individuals whose ancestry is from a single population.
In this effort, they seek unrelated individuals who do not share large segments or chunks of DNA with each other due to recent common ancestry. They also apply quality control measures such as principal component analysis (PCA) to remove outliers: individuals whose genetic ancestry does not coincide with their reported genealogical ancestry or whose genetic profiles are extremely dissimilar to other individuals from the same tested population. Through this process, DNA testing companies can identify markers of DNA that are only found or are predominantly found, in a single population or in a handful of closely associated populations.
Based on sampling methods, residences of test takers and their ancestors, and genetic similarity between the samples in a population, the companies define regions or populations with unique and distinct genetic profiles.

Because companies use different reference panels, they define these regions differently, too. For example, an individual with several generations of ancestry in Denmark may be assigned Scandinavian ancestry by one company, Norwegian and Swedish ancestry by another company, and Germanic ancestry by another company, due to the ways regional boundaries are drawn and defined by the different companies.
While each company is typically able to distinguish between drastically different and geographically distant populations, some may not be able to distinguish as well between geographically adjacent or historically linked populations.
Currently, AncestryDNA’s reference panel has 45,000 samples, 23andMe has 14,000, and MyHeritage has 5,000.[1] Other companies have not reported the size of their reference panels, but they are probably smaller.[2] As more people from a population are tested and included in a reference panel, a more fine-tuned definition of populations becomes possible. Therefore, it is likely that as companies expand their reference panels to include more samples from individual populations, their ethnicity estimates will continually be refined into smaller populations.
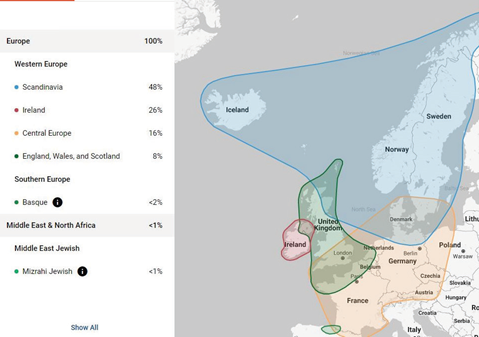
“myOrigins,” ethnic makeup percentage for kit private, private database, FamilyTreeDNA (https://familytreedna.com)
Once a company has assembled a reference panel, it applies different algorithms and approaches to analyze a test taker’s data. Each testing company tests several hundred thousand markers of DNA across a tester’s genome called single nucleotide polymorphisms (SNPs), which are hotspots for genetic variability in human populations. Testing companies analyze a portion of these SNPs as part of ethnicity admixture estimation and consider the prevalence of particular SNPs in specific populations.
Ancestry and 23andMe chop a test taker’s DNA results into smaller chunks or windows of consecutive markers, compare each window to the reference panel and assign the chunk to the population in which its genetic profile is most likely to occur. These chunks and their corresponding assignments are then used to provide percentage estimates of ethnicity regions.
Genetic Communities, Recent Ancestor Locations, and Genetic Groups
Each testing company’s ethnicity estimates report percentages of DNA assigned to populations or regions where a test taker’s ancestors may have lived within the last thousand years. In addition, AncestryDNA, 23andMe, and MyHeritage have started supplementing these estimates with reports of locations and countries where a test taker’s ancestors may have lived more recently and migration patterns in which ancestors may have participated in the last few hundred years.
While broad ethnicity admixture estimates provide high-level context for an individual’s ancestry, these communities, groups, and locations can provide specific clues and hints for follow-up in a genealogical investigation.
Ethnicity estimates consider the prevalence of specific SNP markers in a population and assign percentages of ethnicity, based on similarity to a reference panel. The estimates might be anomalous or unrepresentative of expected ethnicity regions due to historical migrations or population characteristics.
Particular communities, locations, and groups are assigned based on networks of individuals who share large chunks of DNA from recent common ancestors as well as recent ancestral locations, communities, or migration patterns. These communities, locations, and groups are often much more accurate and representative of recent ancestral heritage, although percentages are not assigned to them.
A test taker’s assignment to an unexpected community, location, or group could be due to recent misattributed ancestry or a migration pattern associated with a particular area. A tester from Denmark may have connections to descendants of Danish immigrants to the United States, or a tester from Ghana may find connections to communities of descendants of enslaved communities in the Caribbean.
Why the differences?
Some individuals who test at multiple DNA testing companies receive different ethnicity estimates from them. These differences and changes are not a reflection of the validity of the underlying science, but rather the differences between the reference populations, algorithms, and approaches used by each of the companies.
Even if users test at a single company, it is likely that over the course of several years they will receive updates to their ethnicity admixture estimates. These updates inevitably cause some to complain of their “lost” ethnicities or decreases in their percentages.
Conclusion
In the end, ethnicity estimates are still estimates. As reference panels grow larger, and as companies refine their methods and algorithms for estimation, ethnicity estimates will continue to become more accurate and representative. Even so, ethnicity estimates as they currently stand can provide valuable context and clues for the structure and composition of a test taker’s family tree.
Legacy Tree Genealogists has been at the forefront of genetic genealogy research services for almost two decades. Our team of experts has solved DNA-related cases and can help you solve your family DNA puzzles! Contact us today for a free quote.
Sources
- Catherine A. Ball, et al., “Ethnicity Estimate 2020 White Paper,” Ancestry (https://www.ancestrycdn.com/dna/static/pdf/whitepapers/Ethnicity2020_ white_paperV2.pdf). Eric Y. Durand, et al., “A scalable pipeline for local ancestry inference using tens of thousands of reference haplotypes,” updated 7 December 2020, 23andMe (https://permalinks.23andme.com/pdf/23-16_ancestry_composition.pdf). Esther, “Introducing our New DNA Ethnicity Analysis,” MyHeritage, 1 June 2017 (https://blog.myheritage.com/2017/06/introducing-our-new-dna-ethnicity-analysis).
- Jayne Ekins, “DNA Ethnicity Estimation: Reference Panels,” Your DNA Guide (https://www.yourdnaguide.com/ydgblog/2019/6/6/dna-ethnicity-estimation-reference-panels).
Deja una respuesta